I’m amazed this never came up for me before, but I recently had to diagnose a weird issue where we were seeing shared files locked, preventing other users from accessing them. Thankfully it turned out to be unrelated to the Synology, but I did discover a useful command in the process.
As usual, these advanced commands require that you SSH into the command line interface of the Synology box. You may login as root if using DSM 5.2, or as an admin user/sudo if using DSM 6.0. For the purposes of this blog post I’ll assume DSM 6.0.
So first you remote into the box:
[code lang=”bash”]ssh admin@[synology_IP][/code]
Then run the command “smbstatus” as root via sudo:
[code lang=”bash”]sudo smbstatus[/code]
You’ll be prompted for a password, then it’ll display the output.
First you’ll see a list of client sessions, followed by a list of locked files, similar to the screenshot below.
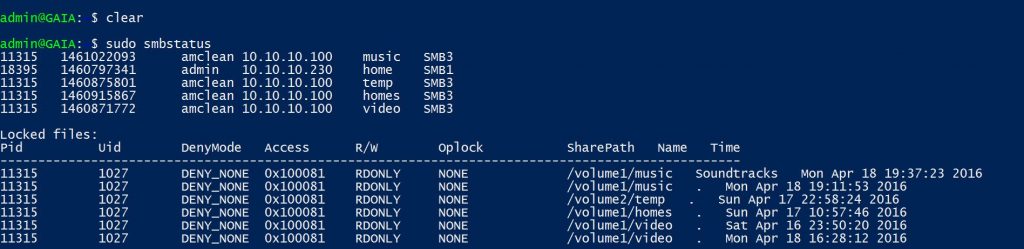
Now the output itself has a few parts as identified by the header. The PID is the process controlling the session or locking the file. The UID is the user that this process is running as. The numbers aren’t very descriptive, but you can reverse search those numbers to get relevant information.
To get the Process Name from UID:
[code lang=”bash”]ps -p 11315-o comm=[/code]
PS is one of the most basic commands in Linux operating systems. In this case we’re using PS to query the PID (as specified by -p [UID]) and then telling it what output format we want (using -o) – in this case “comm” which is the name of the command. Clear as mud? Good. In this example it reveals nothing interesting because we already know the process that has locked these files is the SMB process. The output shows smbd
We can also assume that the UID is the user that is currently accessing or locking the file, but especially in a busy network, it can be useful to identify precisely which user is accessing and/or locking a file. And for this we use a slightly more clunky command to reverse-search the UID.
[code lang=”bash”]awk -v val=1027 -F ":" ‘$3==val{print $1}’ /etc/passwd[/code]
Now AWK is a pattern-matching tool that I couldn’t even begin to explain in this post, but suffice it to say the rest of the command is there to feed it a pattern to match (in this example 1027), find the matching UID row and output the third column value (that is, the name) of the user, all of which is found in the file /etc/passwd. Or put in simpler terms, it looks inside /etc/passwd for the username matching the UID.